


I came across this white paper listed in the references of the book Designing Data-Intensive Applications, which I am currently reading. This whitepaper is yet another very well written and actually address the philosophy of distributed system reliability.
You are welcome to read on your own here is the link.
Jay Kreps: “Getting Real About Distributed System Reliability,” blog.empathybox.com, March 19, 2012.
For others looking for a summary, I’ll share my key takeaways and what I found most interesting. The white paper explains that the internet has centralized a significant amount of computation onto services like Google, Facebook, Twitter, LinkedIn, and other large websites. This centralization places immense pressure on system scalability for these companies. The authors, who have written Voldemort (a distributed database system used by LinkedIn, although it has been discontinued since 2010) and co-founded Confluent along with the co-founder of Apache Kafka, possess deep working understanding and authority from practical working experience to address issues related to distributed system reliability.
It is true that incremental and horizontal scalability is a fundamental feature that requires ground-up redesign and cannot be added incrementally to existing products. Properly designed systems can run with no planned downtime or maintenance intervals, unlike traditional storage systems, which face greater challenges in this regard. Additionally, software explicitly designed to handle machine failures differs significantly from traditional infrastructure. The author explains that distributed systems are not inherently more reliable than traditional systems.
The whitepaper explains the believe of people that distributed system is innately reliable because of replication feature.

Image created by Author using canva

Image created by Author using canva
The flaw in this reasoning is because of below points:
The flaw lies in assuming that failures are independent.
PN represents an upper bound on reliability, but it’s practically unattainable.
In reality, failures are often correlated, and the system’s actual reliability depends on other factors.
The reliability of any system, whether distributed or traditional, depends on several factors:
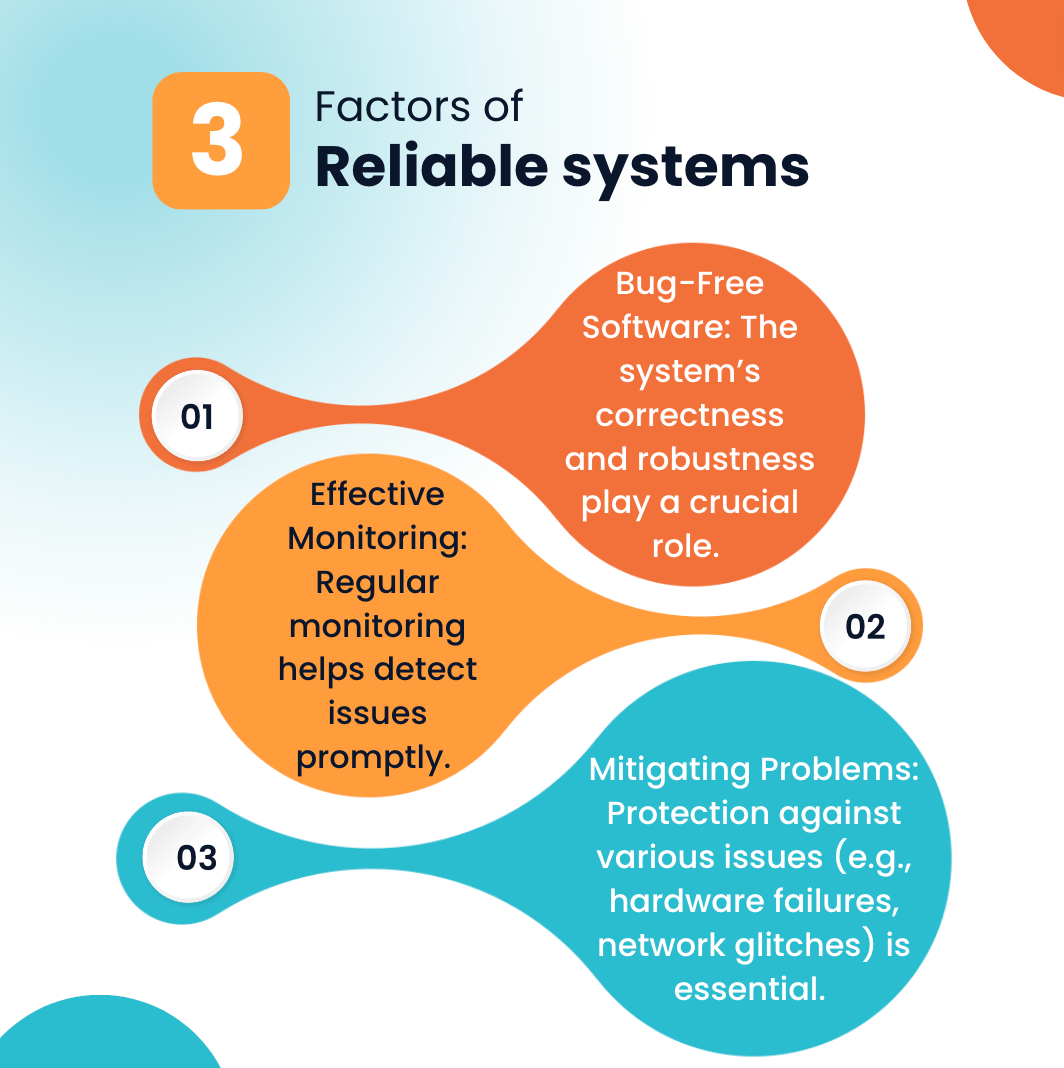
Image created by Author using Canva
While replication is a fundamental concept for reliability in distributed systems, practical reliability depends on factors beyond just replication. Bug-free software, vigilant monitoring, and proactive problem mitigation are critical for both distributed and traditional systems.
Author explains that , distributed system software is inherently more intricate than single-server code. Handling failure cases and ensuring “cluster awareness” is exceptionally challenging. The root issue lies in the vast state space that must be tested and validated.
Dealing with Failures in distributed system is drastically different then single node database. Consider a single-node database: If its disk system suddenly slows down, expecting it to remain fast doesn’t make sense. In contrast, distributed systems must soldier on even in the presence of degraded machines. These “semi-failures” are common but incredibly hard to manage.
Testing Realism in distribution system and bugs propagation is also drastically different than traditional oracle like single code base systems. Realistically testing such scenarios is brutally difficult in distributed systems. Unlike their more mature predecessors like oracle, newer software lacks comprehensive quality assurance (QA) processes. Bugs abound, and they affect all machines simultaneously.
Configuration Challenges, distributed systems demand extensive configuration, often complex due to cluster awareness, timeout handling, and other factors. This shared configuration introduces yet another avenue for potential failures.
Distributed systems grapple with intricate software, testing limitations, and shared configurations — all while striving for reliability in the face of multiple failures.
The Author then give examples from real time incidences of Kafka , Linux and HDFS at Yahoo to elaborate how vulnerable distributed systems could be to bugs and wrong configurations. He believes that its more of good operation conversation rather than architecture or design. I would second the opinion of author that data centric companies understand these challenges and often go for in-house expertise for distributed system operations and maintenance and often through such efforts new innovations also originates. Not every company is operating at such scale and hence can’t justify such investments.
Empirical reliability where system is able to run over year and tolerate the failures backed by monitoring , test and operational procedures are good way to rate the systems compared to theoretical reliabilities. System design has its own value and act as a kind of limiting factor on certain aspects of reliability and performance as the implementation matures and improves, but they are not taken to be guaranteeing anything.
I will leave you with comparison chart and my own conclusion , if your views are different love to hear them in comments.
Traditional vs Distributed systems pros
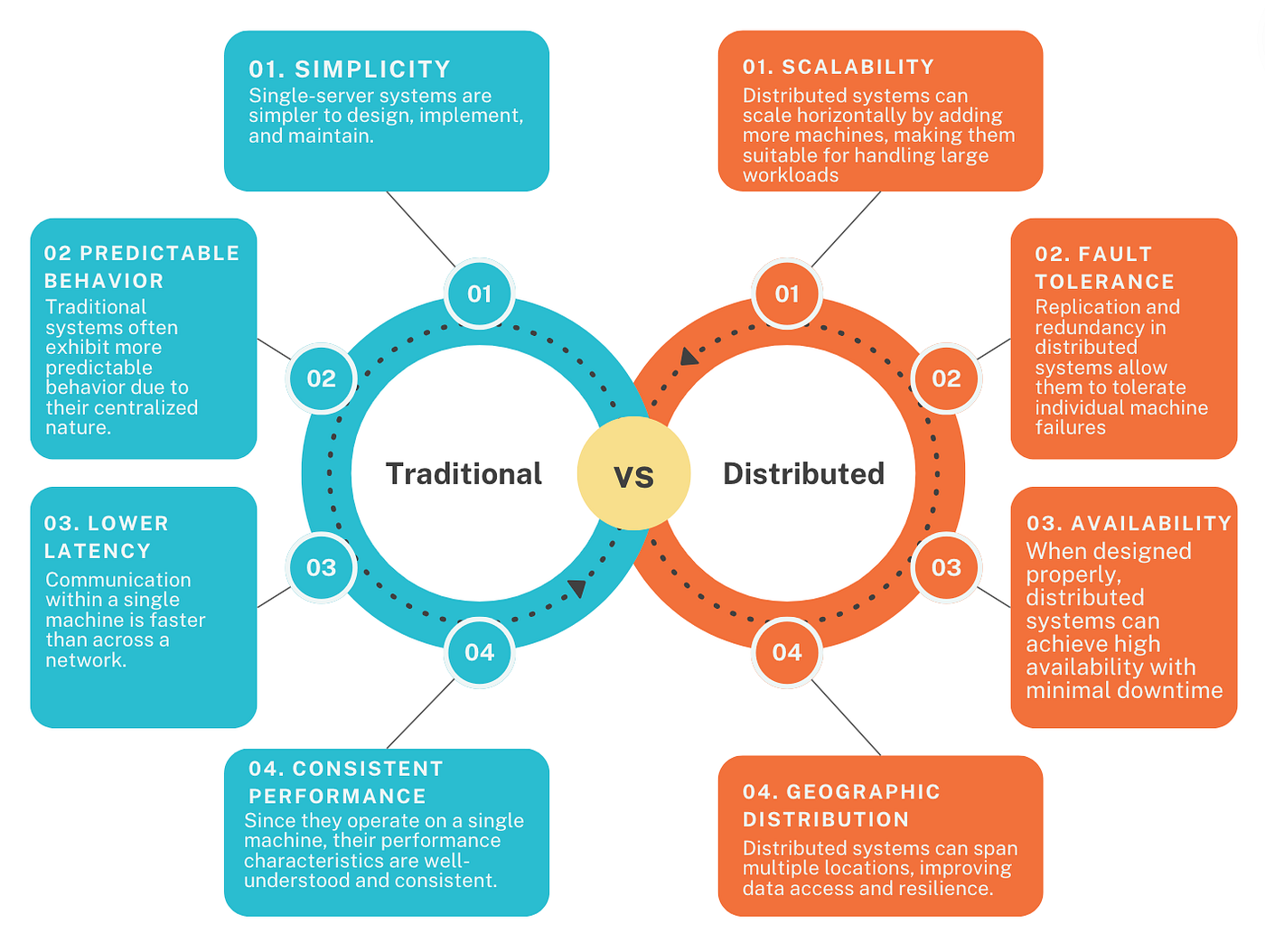
Image created by Author using Canva
Traditional vs Distributed systems cons

Image created by Author using Canva
Conclusion
Neither approach is inherently more reliable; it depends on the specific use case, design, and implementation.
Distributed systems offer better scalability and fault tolerance but come with increased complexity.
Traditional systems are simpler but may lack the scalability and availability needed for modern applications.
With increased data volumes and keeping in mind future scalability, everyone is leaning towards distributed systems. Traditional systems either have to transition to distributed platforms and offer operational support, monitoring, and scalability similar to what AWS and GCP systems are offering now, or become obsolete over time. That’s my opinion; you are free to differ!
I’m diving deeper into Designing Data-Intensive Applications and will be sharing insights on specific whitepapers, concepts, and design patterns that capture my attention. If you’d like to join me on this exploration, consider following me to receive automatic notifications about my next article!