


Consistency is considered hard to achieve in a distributed cluster. Terms like CAP theorem and eventual consistency are used to describe consistency, whereas relational databases are considered consistent because of ACID transactions.
Now, consistency is required in both write and reads. Let’s discuss both:
- Update consistency — To illustrate this concept, let’s consider an example involving bulb suppliers. One of these suppliers has recently changed their address. In this scenario, two business managers, John and Paul, noticed the outdated address and wanted to update it simultaneously. They both have update access, and they both decided to update the address at the same time. Now, to make this example more illustrative, let’s add that John updated the address with the building number, whereas Paul didn’t.
So essentially, the same piece of information is updated by two users, John and Paul, at the same time, but the information being updated varies.
This scenario is called a write-write conflict.
Both users update the same information, and it reaches the server. The server will serialize these updates. For simplicity, let’s decide that the criterion to pick the update is alphabetical. In our scenario, John’s update will go first, and then Paul’s update will overwrite it without any concurrency control, resulting in the loss of the building information.
This example illustrates a failure of consistency because John’s updates were lost.
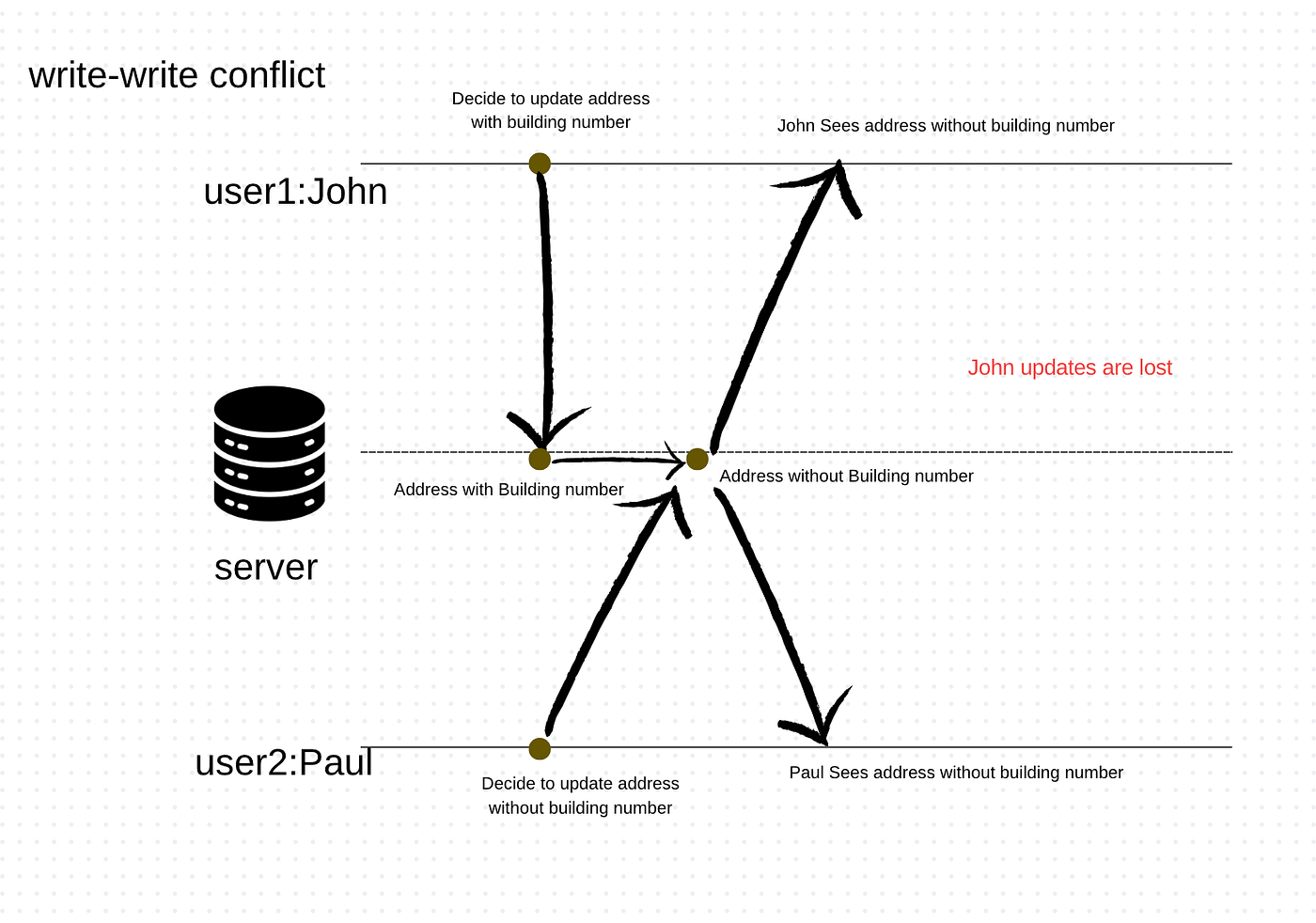
Image created by Author
Approaches for addressing consistency conflicts are described as:
Pessimistic
Optimistic
A pessimistic system works towards preventing conflicts from occurring, whereas an optimistic approach lets conflicts occur and works towards detecting and taking action to sort them out.
In the case of update conflicts, the most common pessimistic approach is to have write locks. This ensures that if you want to update, you have to acquire a lock first. The system ensures that only one user gets the lock at a time. So in our scenario, John would get the lock first, and Paul would get to see his updates before any updates.
A common optimistic approach is conditional update. In this system, before updating, the system checks whether the value has changed since the last update. In our scenario, Paul’s changes would fail, but John’s would succeed. The error message would prompt to recheck the value updated by John.
Both pessimistic and optimistic approaches we discussed above work sequentially for a single server. When the system is distributed, for example in peer-to-peer replication, an update can happen on one node before the other.
Another option for write-write conflict is to save both updates and record that they are conflicts. Especially in distributed systems, you can show both updates to the user and let the user accept one of them.
2. Read consistency
To understand this, let’s imagine a scenario where there are orders and order amounts. Suppose John adds another order item in a relational table where order line items and price information are stored in different tables. Now, Paul reads the amount calculated in the amount table. Then, John goes and updates the order amount value. This is an example of inconsistent read or read-write conflict.
This type of consistency is referred to as logical consistency, meaning different data elements, in this case, order items and order amount, make sense together. In the relational database world, this situation is handled by defining a transaction. So, in the relational database world, both updates are part of one transaction, which ensures that Paul would either read order items and amount before John’s updates or after John’s updates.
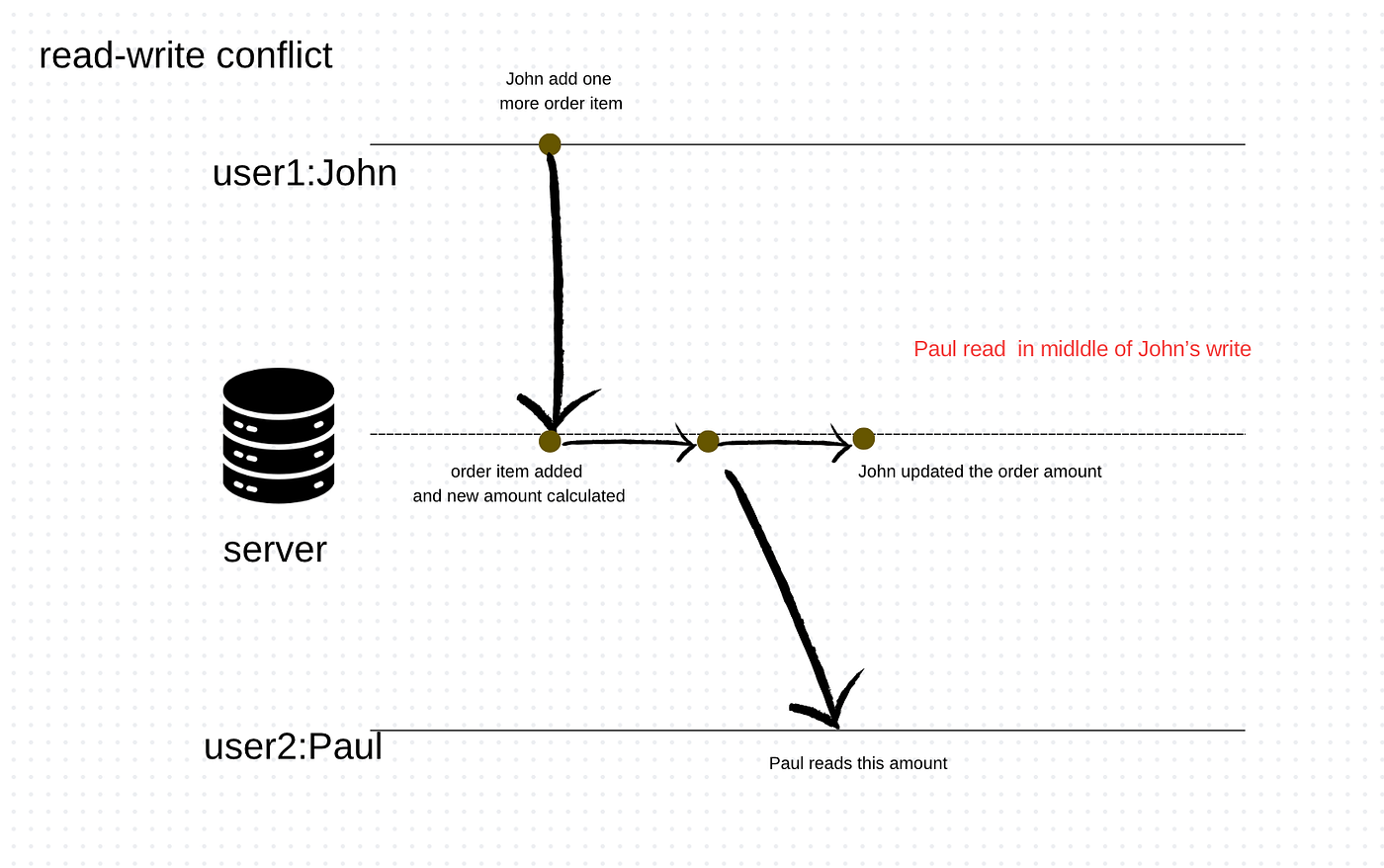
Image created by Author
A common notion is that NoSQL databases don’t support transactions and hence are not consistent. However, graph databases support ACID transactions, same as relational databases.
Aggregate-oriented databases do support atomic updates at the aggregate level. This means logical consistency is maintained within aggregates, for example, orders, items, and amounts in the same aggregate. However, since you can’t pack all the information in one aggregate, updates across aggregates can cause inconsistency in reads. The time period for which this inconsistency occurs is called the inconsistency window. NoSQL databases usually have a very short inconsistency window (around a second or so).
Apart from the logical inconsistency discussed above, in distributed systems with replication, there are new kinds of inconsistencies. To understand this, let’s imagine a scenario where John, who is in Texas, and Paul, who is in Singapore, both want to book a flight. To make the example more relevant, let’s assume all seats of the flight are booked except the last one. Initially, both John and Paul see the last flight ticket unbooked, but then user ‘x’ from London books the ticket. Paul sees it correctly and starts looking for another flight or changes his plan, whereas John in Texas still sees this flight seat available for booking. This is an example of replication inconsistency.
Eventually, all replications will catch up, and hence this is called eventual consistency, meaning that at any time, nodes may have replication inconsistencies but, if there are no further updates, eventually, all nodes will be updated to the same value. Data which is out of date is called stale.
Although replication and logical consistency are different concepts, replication inconsistency on top of logical inconsistency can cause more adverse effects. Consistency is a topic that works with variance within an application. What I mean by this is, based on your business requirements, you can make your consistency requirements tightened or relaxed.
An inconsistency window among two users across locations may not be such a bad thing, but an inconsistency window of updates for a single user is problematic. For example, you are writing a blog, and the application or website is in a distributed network with different nodes for replication and load balancing. You are writing your thoughts, but your article is not showing up — that’s a problem situation. In situations like these, to tolerate your long inconsistency window, you need read-your-write consistency, which means you should be able to see your updates immediately. Usually, this is achieved by using session consistency for a user. Now, if the same user’s session ends or they decide to log in from a different device, the session consistency doesn’t apply, but that’s a rare scenario.
Maintaining a sticky session with primary-secondary replication architecture is challenging if you want to write in the primary and read from secondary nodes for better performance. One way of tackling this would be to send the writes to the secondary node, which is attached to the sticky session, and then this secondary node takes the responsibility to replicate that new write to the primary in order to sync to every other node in the cluster. Another approach would be to switch the session to primary while the writes are active and secondary nodes are catching up in the background for consistent read-your-write consistency.
There are various ways out there to achieve session consistency. One very popular technique is sticky session, which makes all the updates of a user go to a single dedicated node, but now this limits the benefits of the load balancer. Another technique is version control, which we will talk about in the coming article. At a high level, every interaction with data ensures the latest version stamp by session. The server node then ensures it has the latest version before responding to a request.
Consistency is very important and needs to be addressed, but also based on requirements, sometimes it needs to be relaxed and forgone. If you are building an application where performance is your utmost priority and business requirements are such that you have wiggle room for compromising on consistency, one such example I can think of is social media updates and comments. It’s the tradeoff you would need to decide as an architect of your solution.
I’m diving deeper into Designing Data-Intensive Applications and will be sharing insights on specific whitepapers, concepts, and design patterns that capture my attention. If you’d like to join me on this exploration, consider following me to receive automatic notifications about my next article!
In case you have missed my previous article here is the link