
Data Ingestion From Files
https://www.sothebys.com/en/buy/auction/2022/art-impressionniste-et-moderne-day-sale/le-cabinet-anthropomorphique


In Spark, data is transient, meaning that once the Spark engine is shut off, all the data in memory is lost. Since Spark operates on in-memory processing, data is only available while the Spark session is active. Whether you are building an ETL pipeline or conducting analysis, data ingestion is the first crucial step.
The primary purpose of parsers in Spark is to interpret the input data and transform it into a structured representation that can be easily understood and processed by other programs or components. Parsers follow predefined rules or grammar, typically specified as formal grammar or parsing rules.
Spark comes equipped with various built-in parsers, allowing it to efficiently read and ingest data from different file formats and sources. These include CSV parsers, JSON parsers, XML parser, Text parser, Parquet parser, AVRO parser, ORC parser, and more. Each parser caters to specific data formats, enabling Spark to handle diverse data sources seamlessly.
Let’s delve into these topics in detail.
We’ll begin with the CSV parser, as CSV is the most popular file format. We’ll explore two approaches: one where Spark infers the schema automatically and another where we provide the schema beforehand.
When Spark infers the schema, it examines the data in the CSV file and deduces the data types and structure of the columns. This method is useful for situations like ad hoc analysis and running analytical jobs. It’s particularly beneficial when dealing with third-party data dumps where you might lack knowledge of the source systems. However, for large volumes of data collected from diverse sources, some profiling and understanding of the datasets may be necessary to ensure accuracy.
Let’s dive into the CSV parsing methods to gain a comprehensive understanding.
Import the necessary SparkSession.
Create a SparkSession, which is the entry point for Spark functionality.
Use the .read method of the SparkSession to read csv data.
Specify the path to the csv file or directory containing csv files to be parsed.
Optional: Set any additional options, such as the sep and other csv-specific configurations.( I have shown some additional options though it’s not actually uses in reading the sample csv I am using)
Call the .load method to load the csv data into a DataFrame.
Perform further transformations, queries, or analytics on the DataFrame.
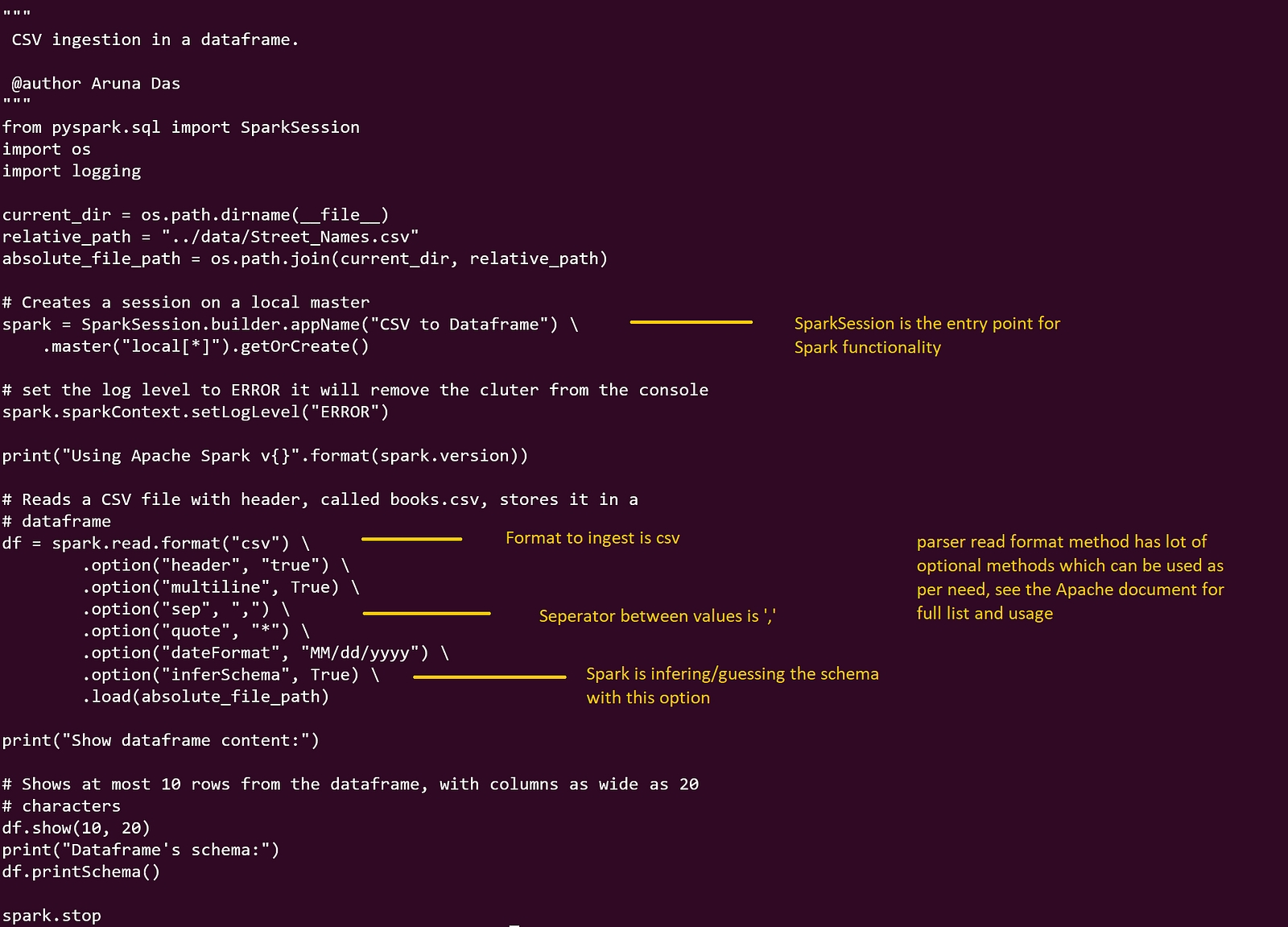
Image By Author
You can trigger the python script using spark-submit.
Once you have the code in script it can be cron , orchestrated.
bin/spark-submit /home/aruna/spark/app/article/SparkSeries/SparkSeries5/csvToDataFrame.py
Output
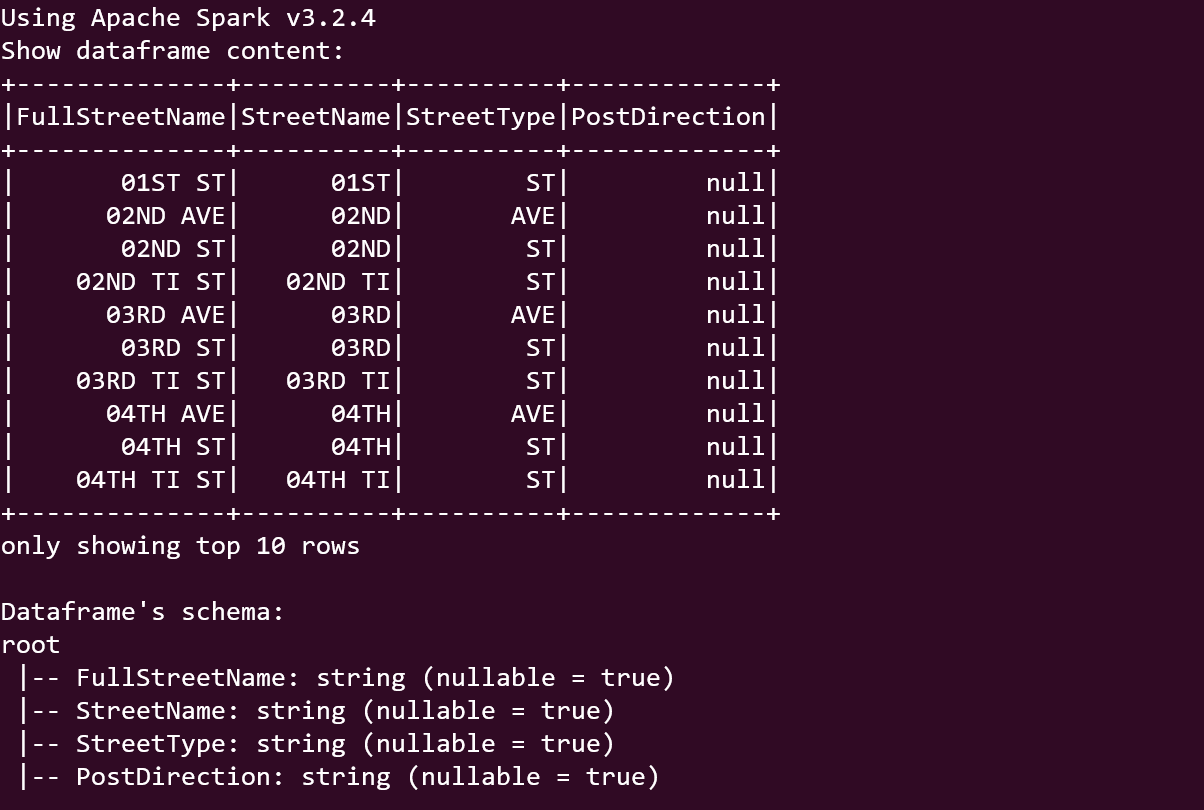
Image By Author
CSV schema is known — This is the preferred method in ETL jobs of production to keep ambiguity and adventure at bay
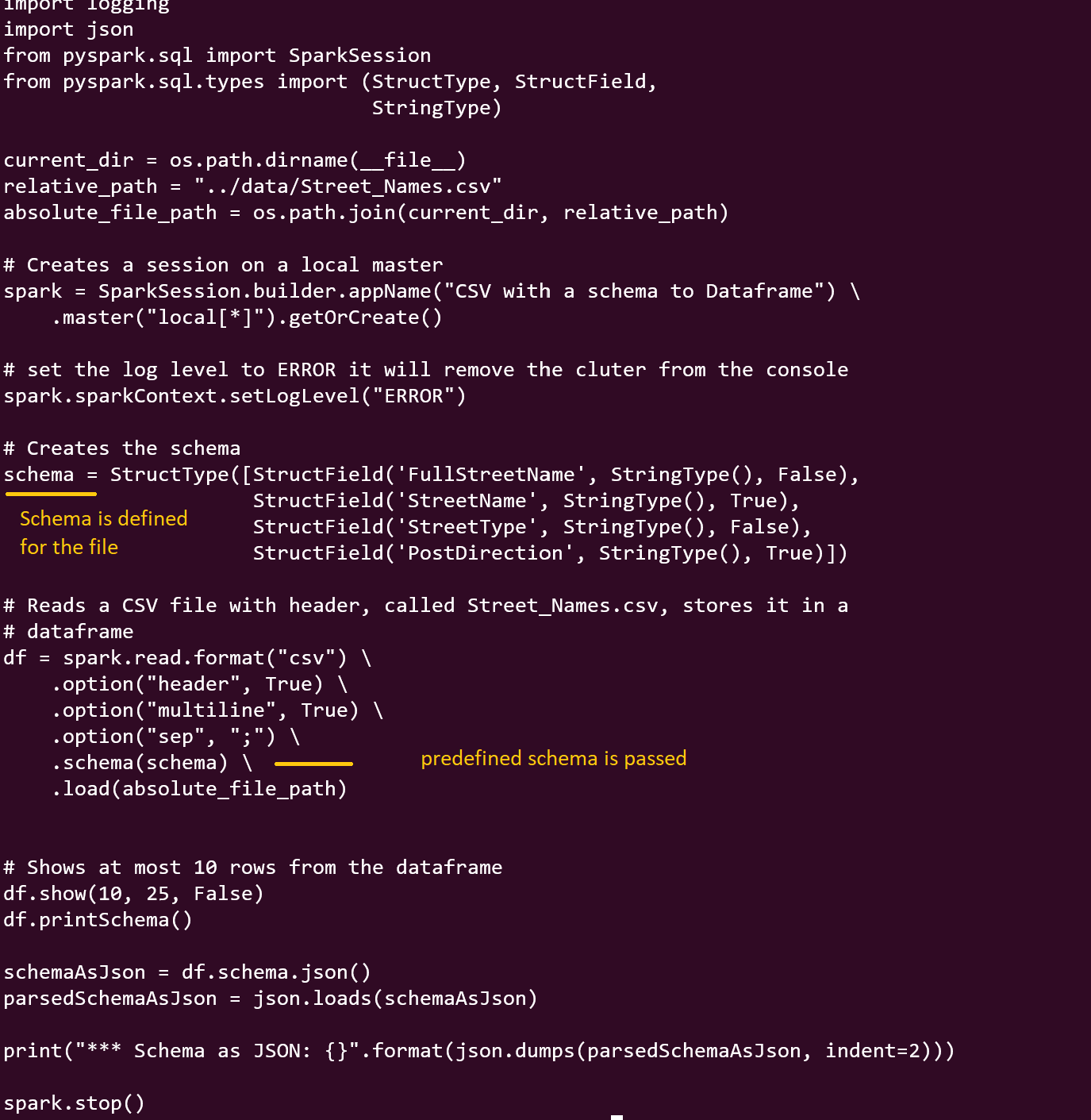
Image By Author
Output
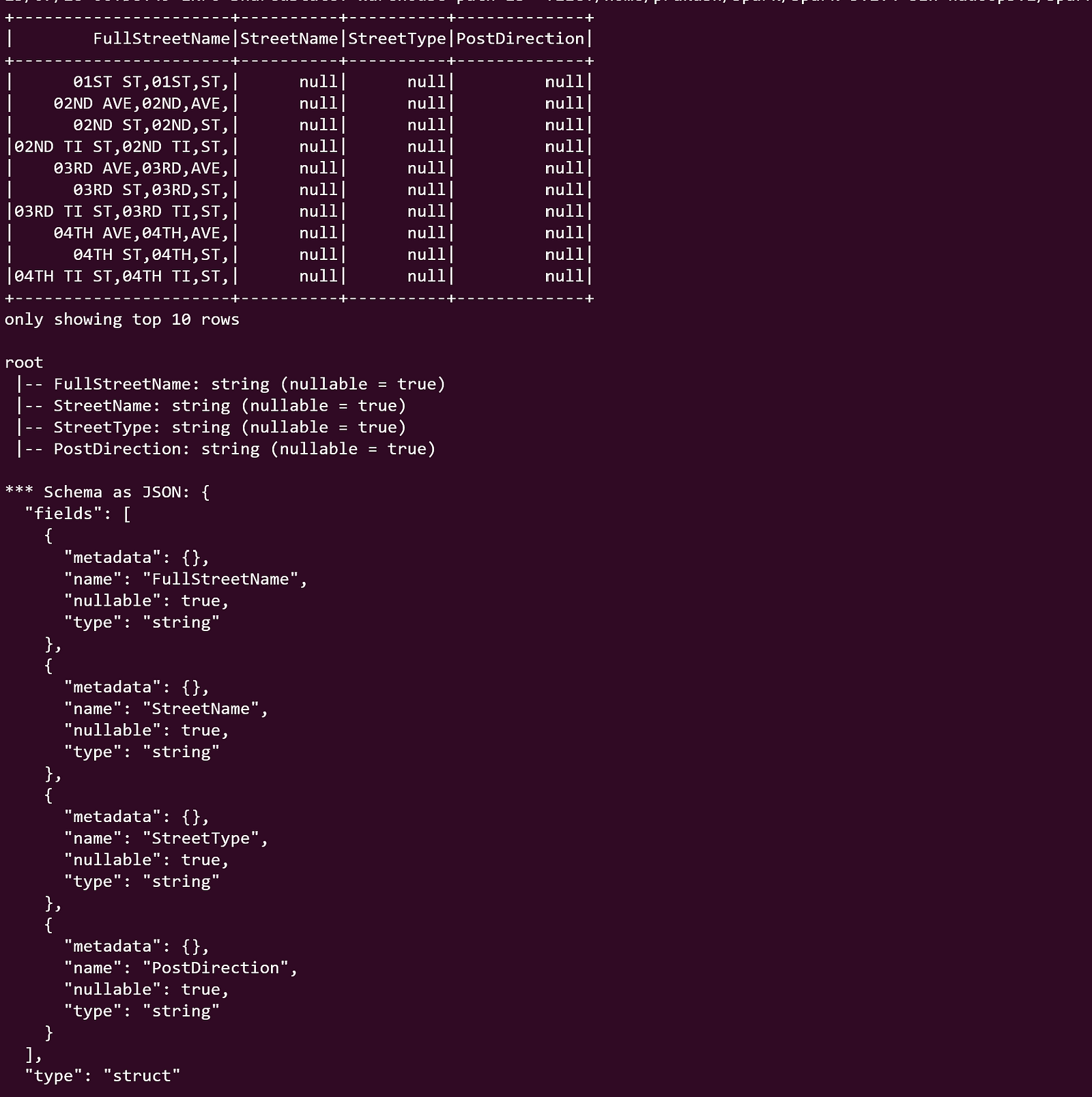
Image By Author
2. JSON parser — Spark’s JSON parser allows you to read data stored in JSON (JavaScript Object Notation) format. It can handle nested JSON structures and automatically infer the schema from the JSON data. Spark support’s JSON lines or multiline . We will look at multiline in this example.
Source file — I used python json and csv library to convert csv file to JSON for this exercise, code can be found in github directory under util.
JSON is great for transporting data but its challenging to traverse it for analytics because of its hierarchical structure. Denormalization or flatting of JSON is required for analytical purposes spark provide many static functions to help facilitate this, explode() is very useful it creates new row for each element in a given array.
Similarly, nested document can be created for transfer and storage. If you interested in these use cases please indicate in comment section I will create future series covering these topics.
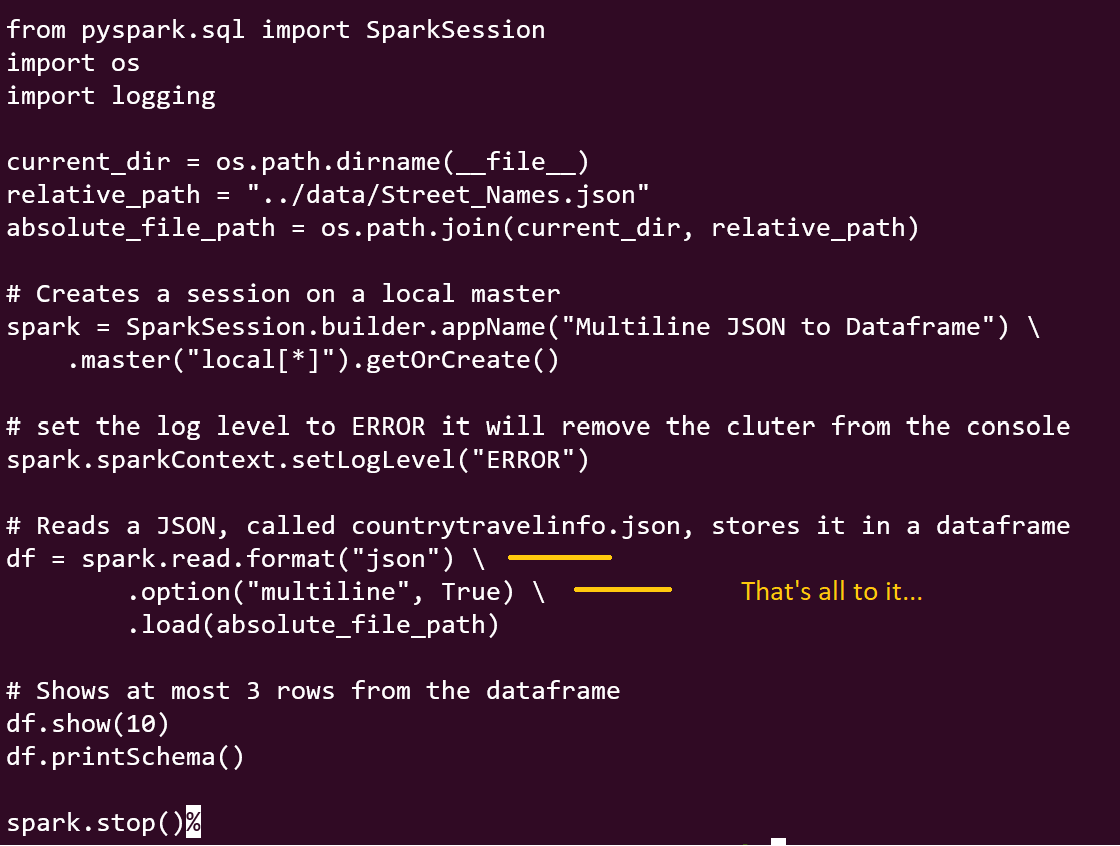
Image By Author
Output
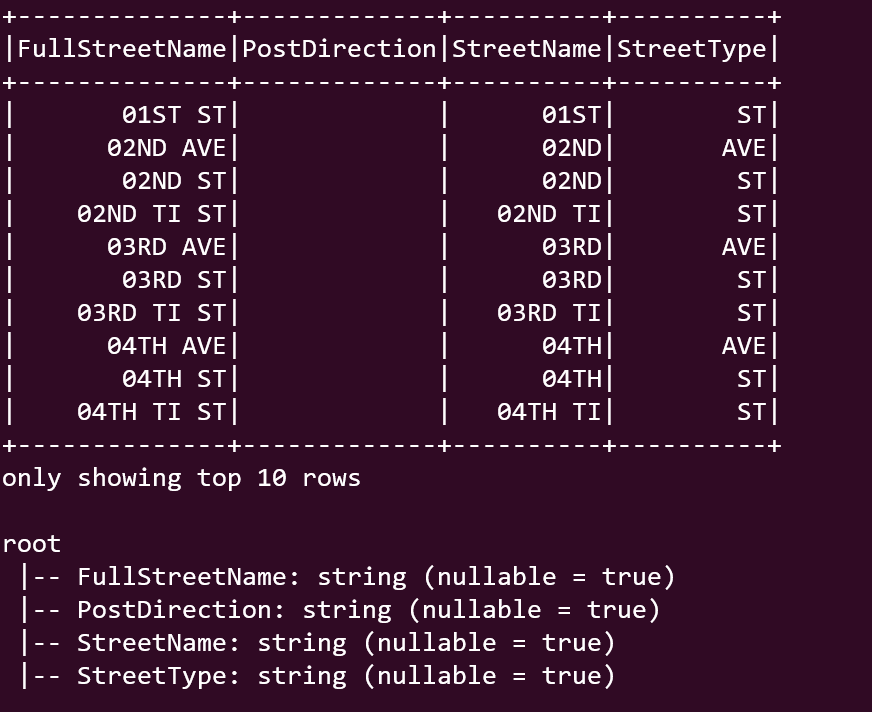
Image By Author
3. XML parser — In Apache Spark, parsing XML data is supported through the “spark-xml” library, also known as “spark-xml” or “spark-xmls.” This library provides the necessary functionality to read and process XML data in Spark.
To use the spark-xml library, you need to include it as a dependency in your Spark application. The XML data can be read into a DataFrame, allowing you to perform various operations on it.
This is little bit more involved for xml parser to work you will have to install the package from databricks, at the time of testing I installed com.databricks:spark-xml_2.12:0.12.0 from databricks.
For running the code from spark-submit you will have to pass the spark-xml package then the python script.
bin/spark-submit — packages com.databricks:spark-xml_2.12:0.12.0 /home/aruna/spark/app/article/SparkSeries/SparkSeries5/xmlToDataframe.py
Import the necessary SparkSession and the spark-xml library.
Create a SparkSession, which is the entry point for Spark functionality.
Use the .read method of the SparkSession to read XML data.
Specify the path to the XML file or directory containing XML files to be parsed.
Optional: Set any additional options, such as the row tag and other XML-specific configurations.
Call the .load method to load the XML data into a DataFrame.
Perform further transformations, queries, or analytics on the DataFrame.
Source file — I used developers option with created XSD to convert csv file into XML using Excel functions.
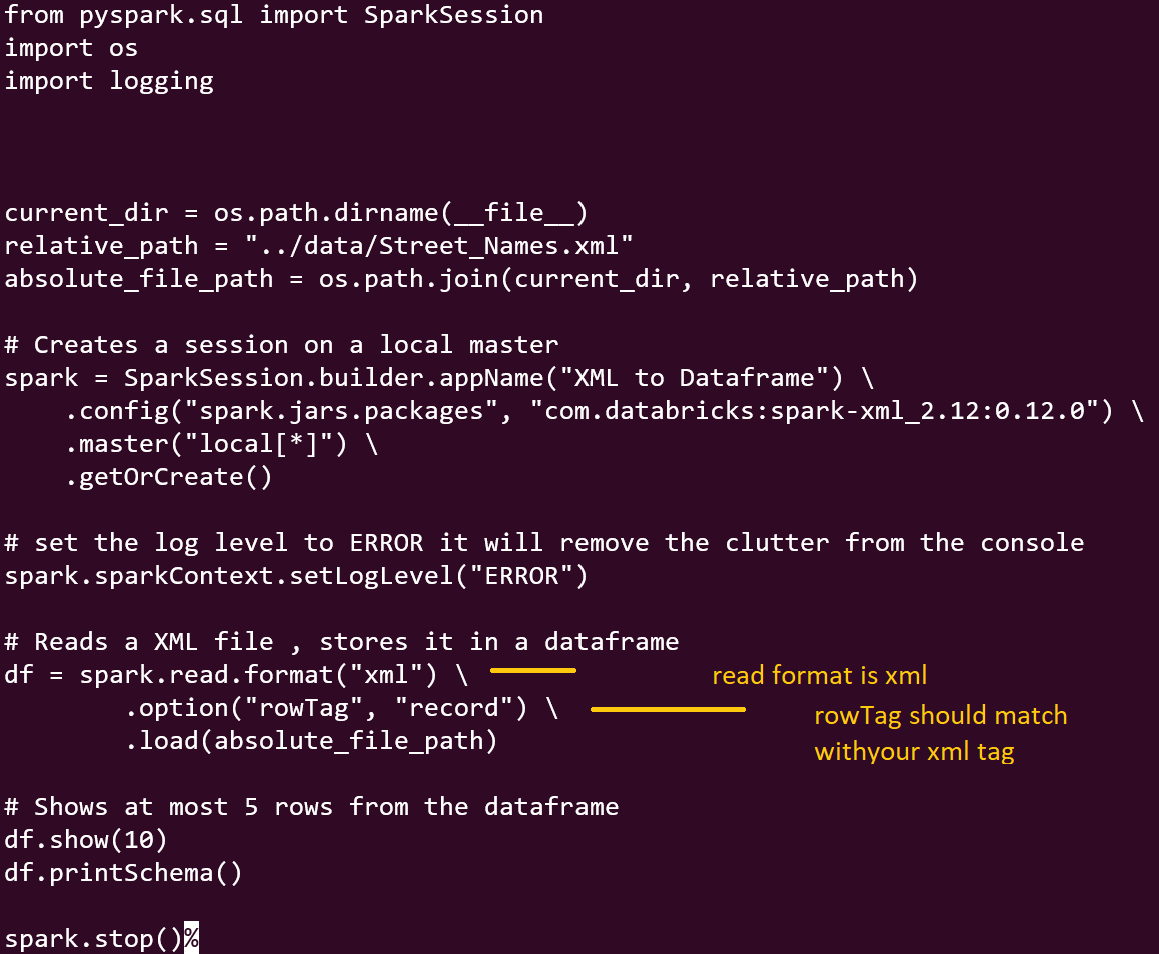
Image By Author
Output
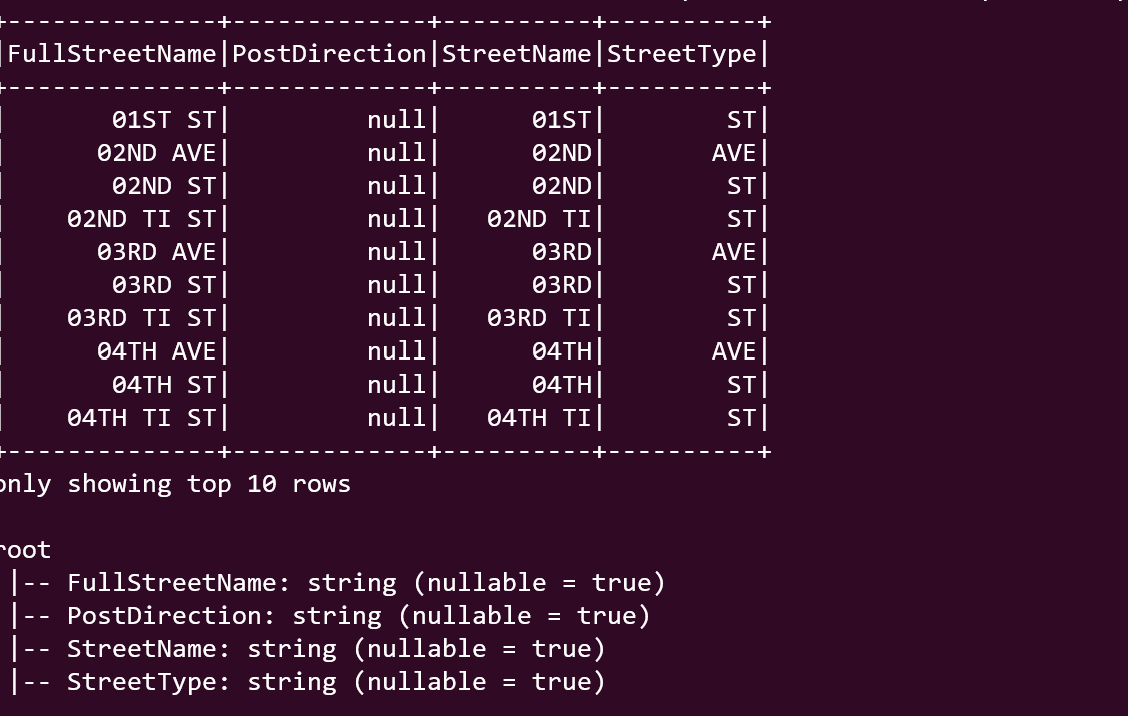
Image By Author
4. Text File — Text files are not very popular but they keep showing up at adhoc level or as a workaround solution or part of legacy so it’s good to know they are accommodated in spark as well.
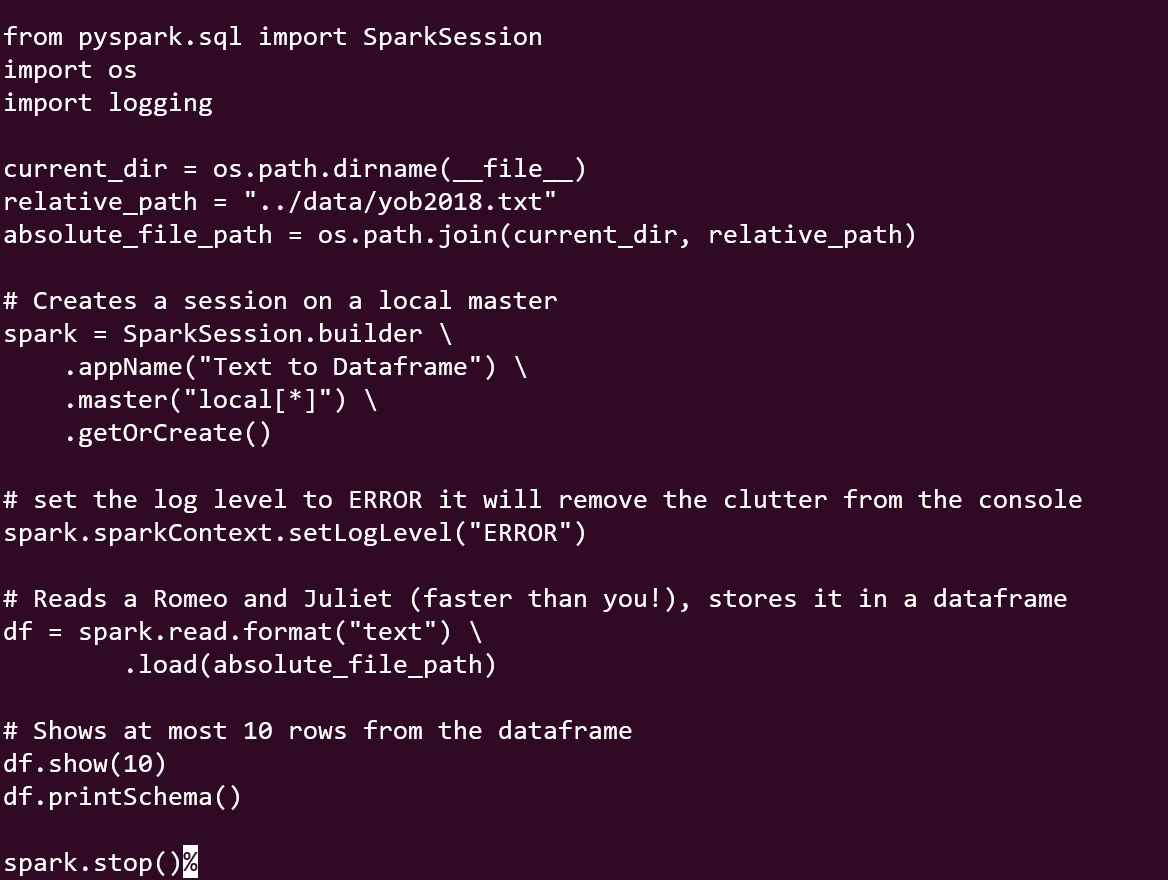
Image By Author
Output
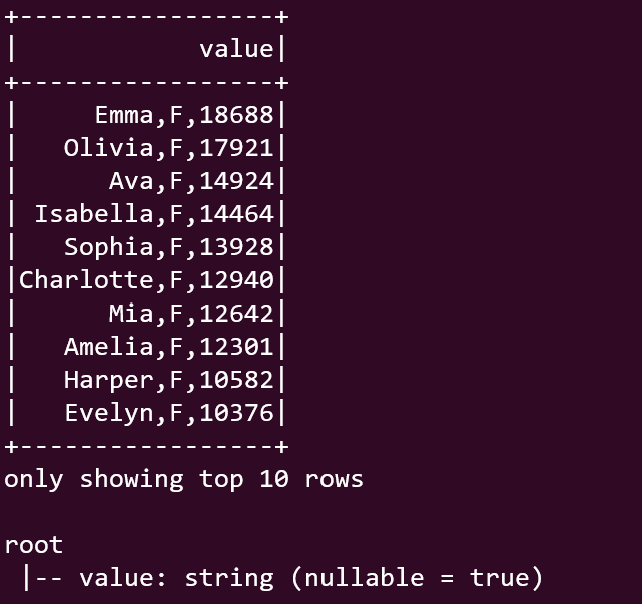
Image By Author