Distribution Decisions : What are your options? — 6

With an increase in data volumes, scaling up becomes costly and, beyond a certain point, impossible. NoSQL has the ability to run a database on a large cluster. Depending on your distribution model, the datastore can handle large quantities of data, whether it’s processing greater read or write operations, or providing more availability or consistency in case of network partition (CAP Theorem). Running over a cluster is a complex endeavor.
There are two options for the data distribution model:
Replication — primary-secondary and peer-to-peer.
Sharding.
Replication and Sharding are orthogonal techniques, which means you can use either or both of them.
Now let’s delve into these options. The simplest and most acceptable option is a single server. Analyze your requirements; if it’s not necessary, opt for a single server because running a distributed cluster server requires expertise and involves complexity.
Sharding — (Also known as share nothing)
Sometimes a database becomes busy because users are accessing different parts of the dataset. We can support horizontal scaling by distributing these data parts across different servers — a technique known as sharding. In theory, different users access different servers for rapid response; for example, if there are 10 servers, each one has to handle 10% of the load.
However, theory doesn’t always align with reality. In the best-case scenario, a user gets their data from a single server. Therefore, the responsibility lies on the data model design to group all relevant pieces together. This is where the aggregate role comes into play, which we closely examined in our last article.
How to arrange data on nodes can be based on different strategies. One strategy could be proximity to location; it makes sense to keep North America users’ data in North American nodes or datacenters to reduce latency and improve fetch speed.
Another strategy could be load balancing, where aggregates need to be distributed evenly. However, in practice, this can be tricky because over time, the load can become lopsided, requiring re-sharding or rearranging aggregates for even distribution. Many NoSQL products provide features like auto-sharding, something to explore if it matches your use cases.
For scenarios where data needs to be read sequentially, it makes sense to keep the aggregates together.
Sharding alone does only so much for your architecture. When sharding is used with replication, then you see the true benefits because if a node goes down and you don’t have replication, the partial user base accessing this node will be severely impacted.
It’s important to note that while sharding has its advantages and makes a strong case for adoption, it’s also essential to consider challenges related to re-sharding and availability when deciding to go down the sharding route.
Shared-Disk : In this model, all nodes in the cluster share access to a common storage system or disk. This shared storage allows any node to access any data, regardless of where it is stored physically. Shared-disk architecture simplifies data access and management but can introduce potential bottlenecks and performance issues due to contention for access to the shared storage.
Shared-Memory : In this model, all nodes in the cluster share access to a common memory space, allowing them to directly access and manipulate shared data structures. Shared-memory architecture provides high performance and low-latency access to shared data but may be limited by the physical memory capacity of the cluster and can introduce complexity in managing data consistency and concurrency.
Sharding can be vertical or horizontal depending how you want to organize your data and is your business use case.
Vertical –Sharding
Example — user –profile
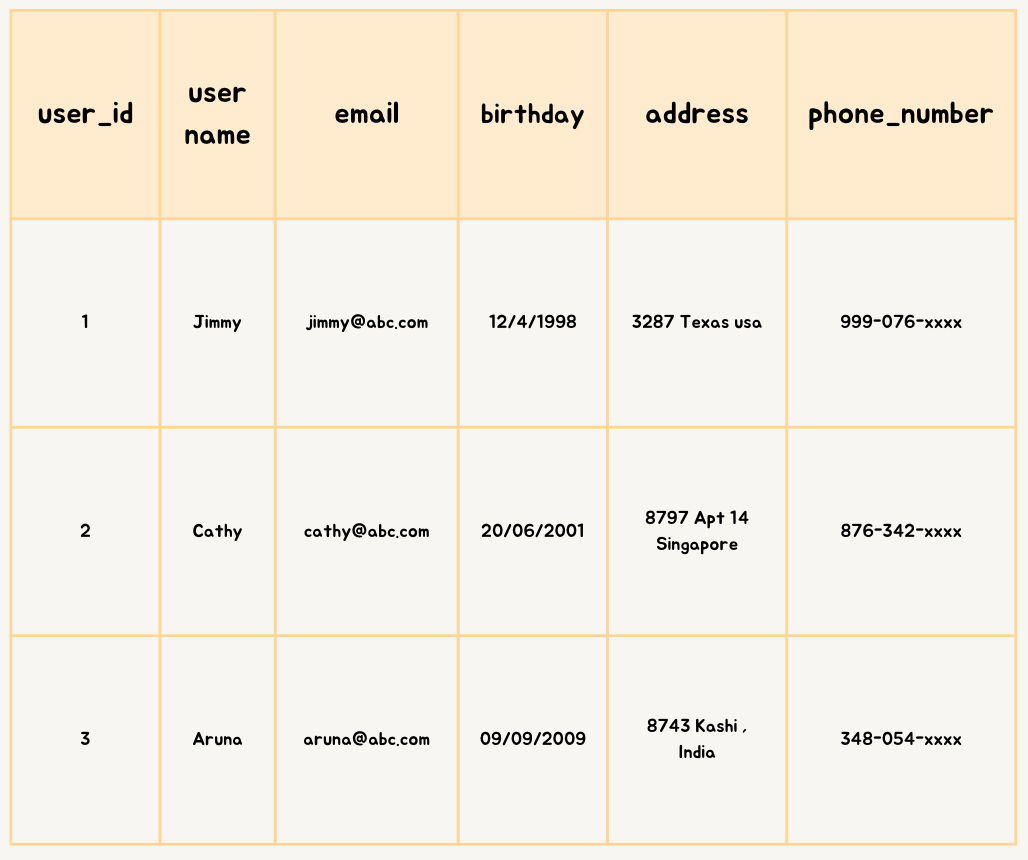
Image created by Author
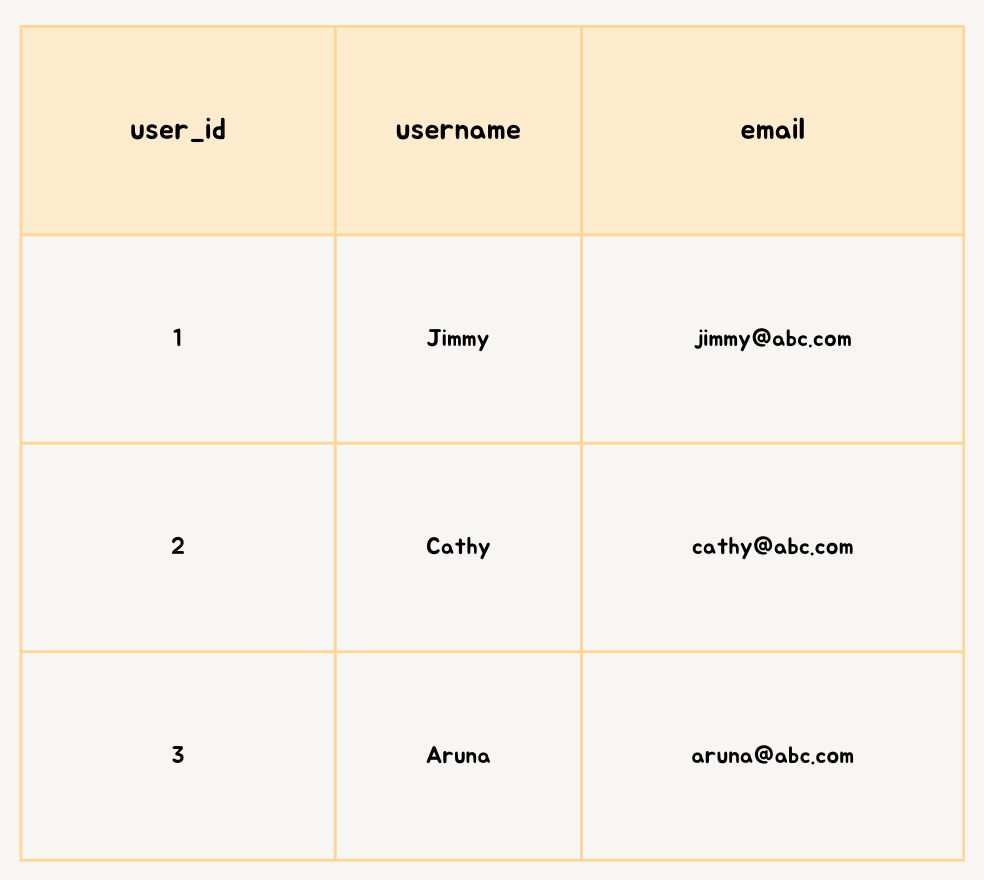
Image created by Author
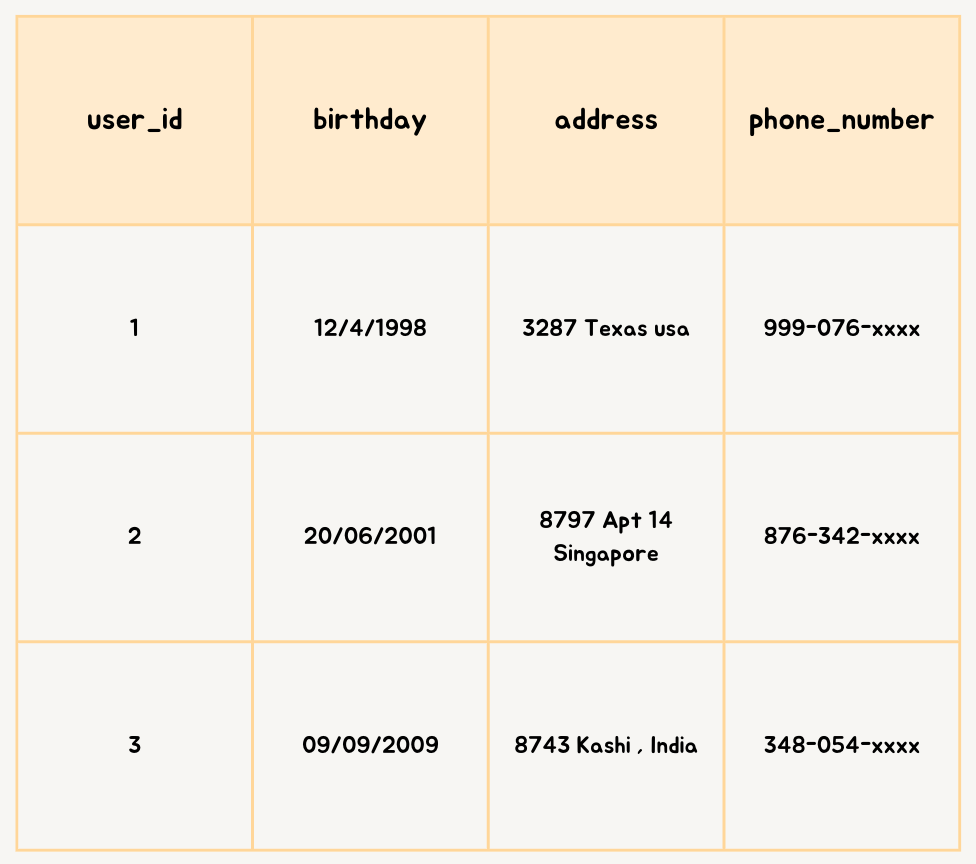
Image created by Author
Horizontal sharding
Example — e-commerce product catalog
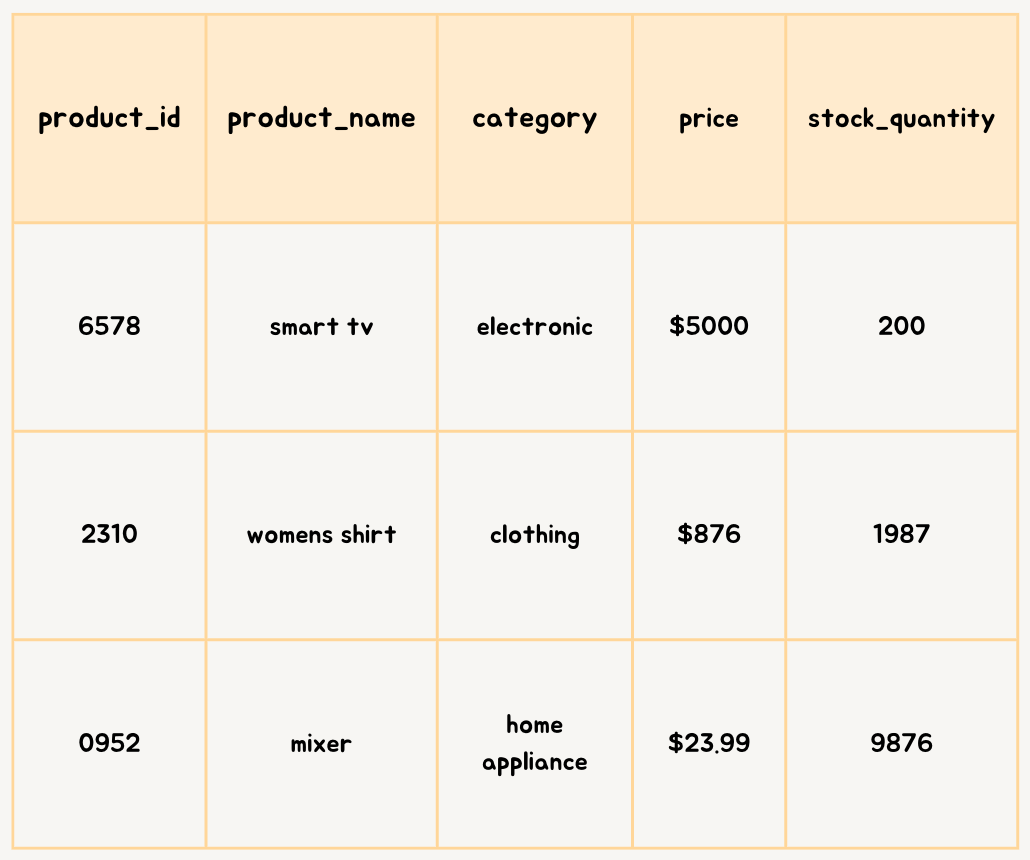
Image created by Author
Electronics Shard

Image created by Author
Clothing Shard
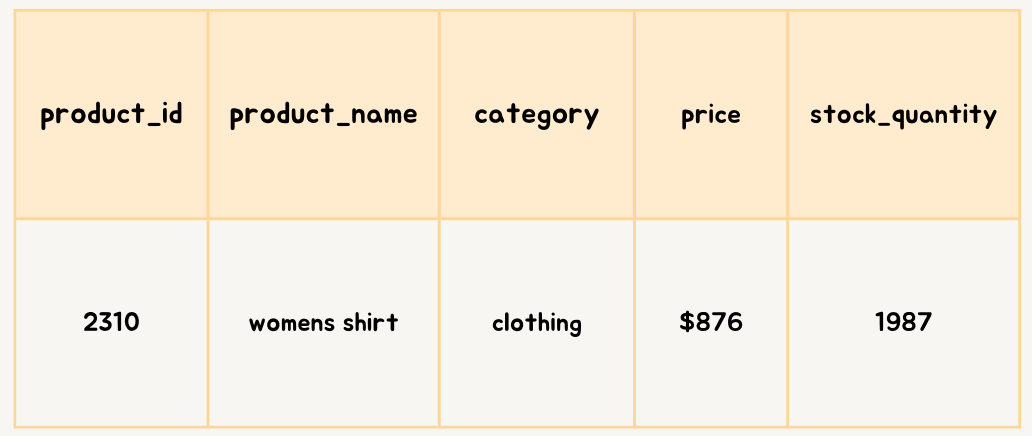
Image created by Author
Home Appliances Shard
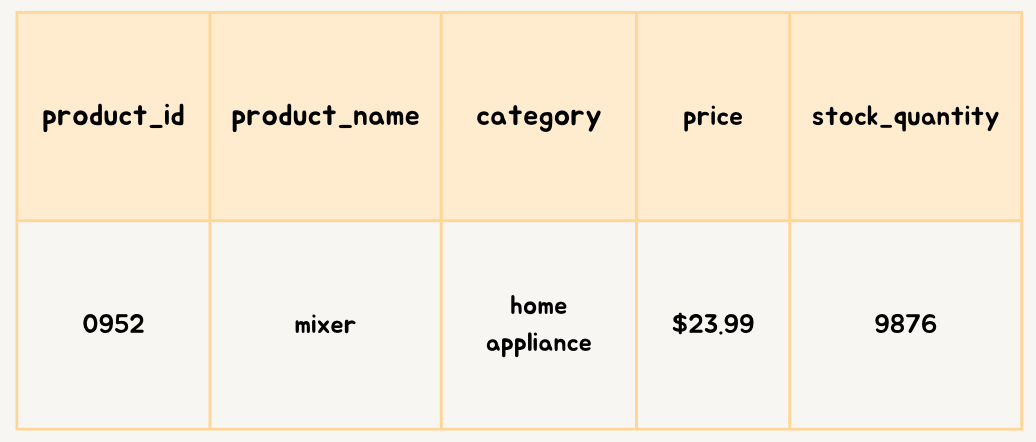
Image created by Author
Primary — secondary replication
In a primary and secondary node system, one node is designated as the primary, which is authoritative and handles updates to the data. This primary node machine is typically of higher caliber compared to the secondary ones. The other nodes are secondary, whose job is to synchronize with the primary.
Primary and secondary replication is most useful in read-heavy systems, where secondaries are given the responsibility to handle read requests. However, this system is only as successful at handling the write/update process and replication to secondaries by the primary. If the requirement is write-heavy, then this setup is not helpful in those scenarios.
Another advantage of the primary-secondary system is read resilience. In case of primary failure, secondaries can still handle read requests. While the failure of the primary node impacts writing, the recovery can be fast because the secondary nodes can have a different healthy primary to handle writes, and the replication sync can catch up.
The primary can be appointed manually or automatically. Manually means appointing a node during configuration, while automatic means designating a cluster of nodes for the primary, which in case of failure will appoint the next healthy one as primary among themselves.
Replication is all a happy story until the secondary nodes go out of sync. In those cases, you will get inconsistent reads across different nodes. Consistency could be a challenge in this setup, so account for that!
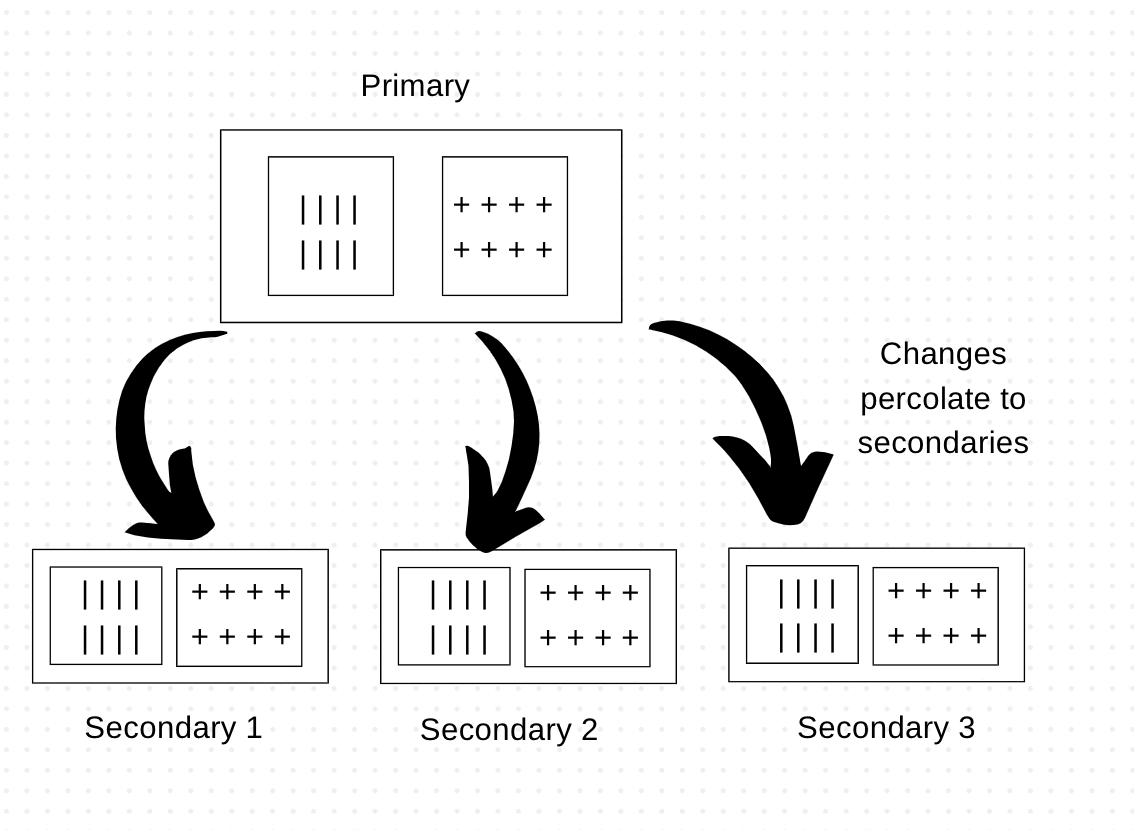
Image created by Author
Peer to Peer replication
Primary-secondary replications help with read resilience but can’t do much for write scalability. While primary-secondary provides resilience against the failure of secondary nodes, it doesn’t protect against write or primary node failures. Thus, the primary node is a single point of failure for the primary-secondary construct. Peer-to-peer addresses this issue where there is no primary; all the replicas have equal weight, and they can all accept writes. If any node goes down, the data is still accessible.
In this case, node failures don’t cause access to data. Additionally, you can add more nodes to improve your performance. However, the challenge in this system is consistency. When you allow writes simultaneously, there is a risk that two writes are trying to update the same piece of data, leading to write inconsistency. We will address the consistency issue and how to handle these in the next article. For now, at a higher level, whenever there is a write, the replicas coordinate to ensure we avoid conflicts. Not all replicas need to agree on the write conflict; majority agreement will suffice, even if we lose a few replicas.
On the flip side, we can adapt the design to cope with inconsistent writes. Policies can be defined in case of conflict and to merge write inconsistencies. This has an overhead but addresses the performance benefits of writing to any replica.
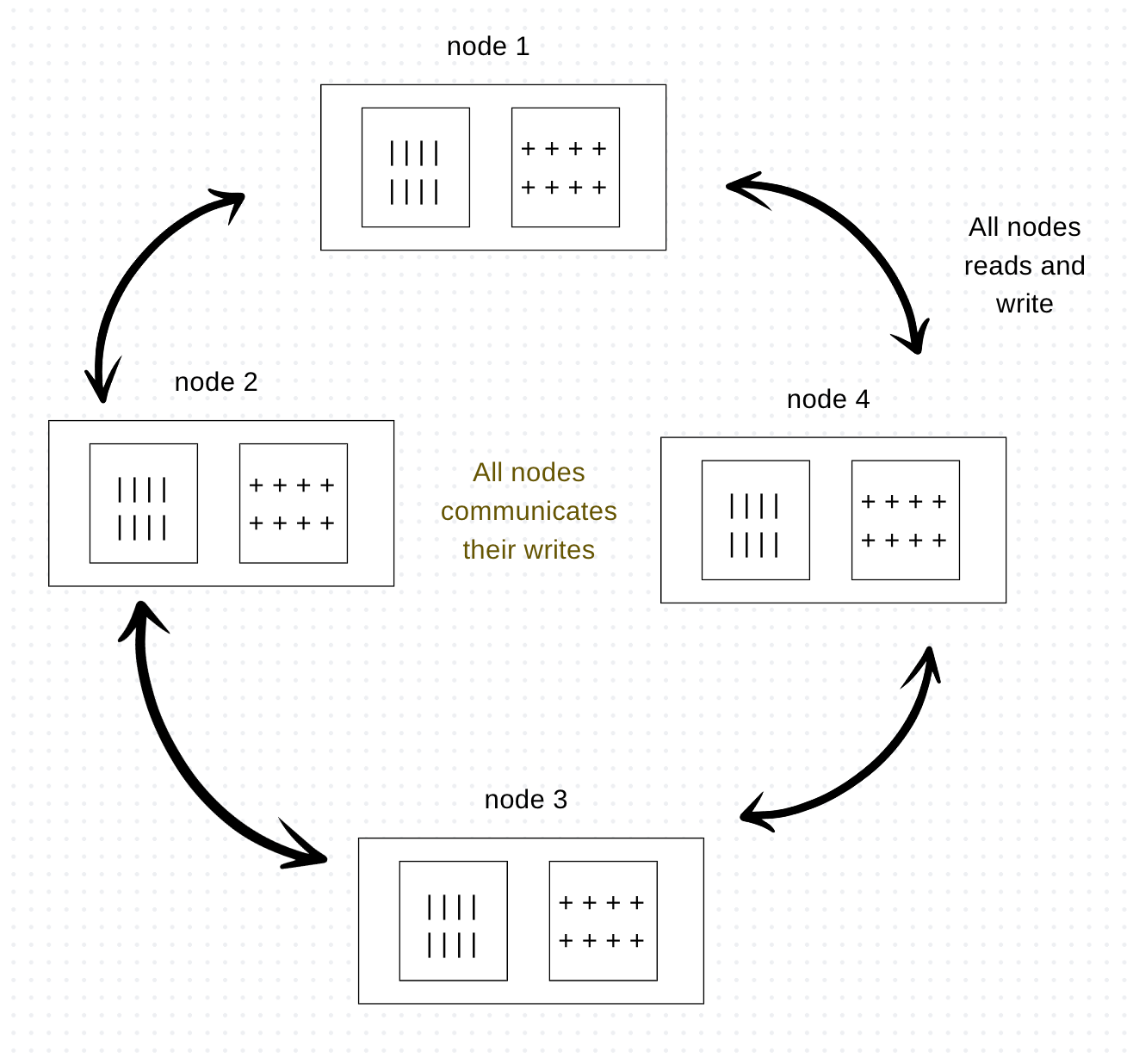
Image created by Author
Combining sharding and sharding
These two strategies of sharding and replicas can be combined to achieve the best results. When you combine primary-secondary and sharding strategies, it means there are multiple primaries, but each data item has only a single primary. Depending on how you configure your system, you have the choice of making a node primary for some data and secondary for others. Alternatively, there are dedicated nodes for primary and secondary; I have seen this combination more often, where the primary cluster consists of expensive high-end nodes, and the secondary nodes have somewhat ordinary configurations.
Another combination could be peer-to-peer with sharding, which is very commonly found in columnar-family databases. The trick in this case is to choose the replication factor. For example, if you choose a replication factor of 3, then each shard is present in 3 nodes. If a node fails out of this group of 3, then a new node has to be built to replace the failed one.
I’m diving deeper into Designing Data-Intensive Applications and will be sharing insights on specific whitepapers, concepts, and design patterns that capture my attention. If you’d like to join me on this exploration, consider following me to receive automatic notifications about my next article!



