
Spark Series #5 : Optimizing Storage Through Format Choices: File Storage Avatars Explored
Image credit - Created by Aruna Das using AI


To delve into the intricacies of Spark’s functionality, it’s essential to begin with a broader perspective. Let’s first explore the world of file storage formats, particularly those tailor-made for distributed computing, such as Avro, Parquet and ORC.
- CSV (Comma-Separated Values)
Year Invented: 1972 (proposed by IBM)
Use Cases: CSV is a simple and widely used file format for storing tabular data. It consists of plain text where each line represents a row, and columns are separated by commas, it started with ‘,’ but evolved into ‘|’ , ‘:’, etc. For me ‘C’ symbolizes a character more than a comma. CSV files are easy to create, read, and import into various software applications, making them popular for data exchange between different systems and databases.
2. XML (eXtensible Markup Language)
Year Invented: 1996
Use Cases: XML is a markup language designed for storing and exchanging structured data. It is widely used for data representation and configuration files, as well as in web services and data exchange between applications. I remember my early years of a software engineering job of working on hours figuring out XSD’s, XSLT depending on which tool I am assigned. Over the years at least in my job experience, I noticed the popularity of XML going down, I am sure there must be applications out there that are still using this format and tightly coupled schema validation. Please share your view I would love to know your perspective.
3. JSON (JavaScript Object Notation)
Year Invented: 2001 (popularized by Douglas Crockford)
Use Cases: JSON is a lightweight data-interchange format that is easy for humans to read and write and easy for machines to parse and generate. It is commonly used for data storage and exchange between web applications and APIs. It’s very popular and successful I don’t see its going anywhere soon.
4. Thrift
Year Invented: 2007 (by Facebook)
Use Cases: Thrift is a scalable, cross-language framework for serializing and deserializing structured data. It is used for communication between different services and systems, especially in large-scale distributed systems where performance and efficiency are critical. Thrift allows you to define data types and interfaces in a platform-independent manner and generate code in multiple programming languages.
5. Protocol Buffers (protobuf)
Year Invented: 2008 (by Google)
Use Cases: Protocol Buffers, commonly known as protobuf, is another cross-platform data serialization format. It is designed to be compact, efficient, and extensible. Protobuf is widely used for communication between microservices, storage, configuration files, and more. Like Thrift, protobuf allows you to define data structures and generate code in various programming languages.
6. RC File (Record Columnar File)
Year Invented: Around 2008 (by Facebook)
Use Cases: RC file is a columnar storage file format optimized for big data processing frameworks like Apache Hive. It stores data in a columnar format, which allows for efficient compression and better performance during analytics queries. RC file is commonly used in data warehousing and analytical processing in Hadoop ecosystems.
7. Avro
Year Invented: 2009 (by Apache Software Foundation)
Use Cases: Avro is a data serialization system that supports both binary and JSON representations. It is used for data exchange between systems and languages, as well as for data storage in Hadoop ecosystems.
8. Parquet
Year Invented: 2013 (by Cloudera and Twitter)
Use Cases: Parquet is a columnar storage file format optimized for use in big data processing frameworks like Apache Hadoop. It is designed to store nested and complex data structures efficiently, making it suitable for analytical workloads.
9. ORC (Optimized Row Columnar)
Year Invented: 2013 (by Hortonworks, Facebook, and Microsoft)
Use Cases: ORC is a columnar storage file format designed for high-performance analytics. It is optimized for use in Hadoop ecosystems and provides efficient compression, predicate pushdown, and lightweight indexing for fast data processing.
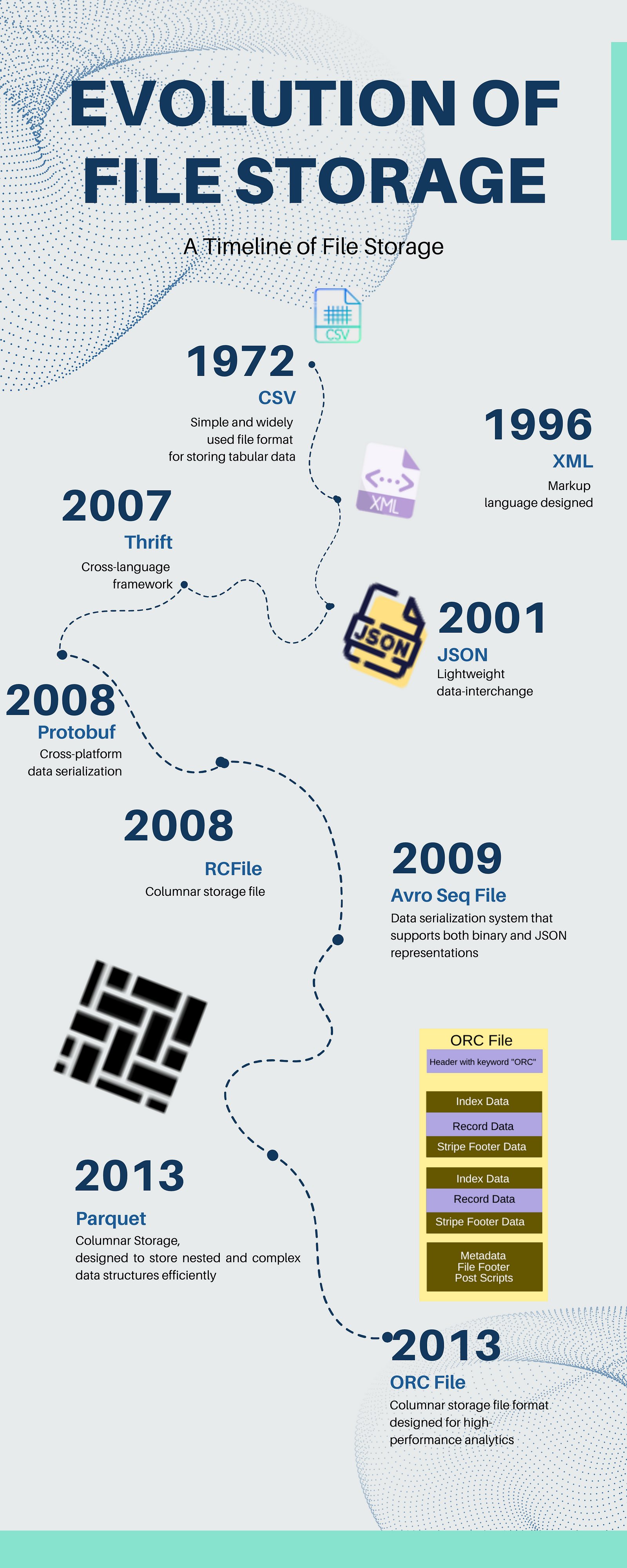
Image Source — By Author
In many cases, the choice of storage file format for the jobs you work on has likely been determined beforehand. It could be influenced by technology preferences, certain companies favoring specific formats or decisions made by engineers in the early stages of the environment. However, I strongly recommend familiarizing yourself with the inner workings of these storage files. Understanding them can be invaluable in optimizing the performance of long-running jobs and shedding light on underlying behaviors that may impact your work.
Big Data file storage format evaluation considerations
Below are some pointers for you to think if you find yourself in the designing phase of early setup. Choosing a Big Data file storage format evaluation framework involves considering several key factors to ensure the selected format meets your specific requirements. Below are a few pointers I can think of to help you in the evaluation process:
Understand Your Requirements
Identify the type of data you’ll be dealing with (structured, semi-structured, unstructured).
Consider the size of the data and the volume of data you’ll be handling.
Determine the level of data compression and performance needed.
Assess the query and analytics patterns you’ll be using on the data.
Consider the compatibility with existing tools and frameworks in your data ecosystem.
This is the most crucial phase and most of the time this is rushed due to making everything agile and publishing deliverables.
In my opinion, this is the most crucial phase which requires a very high level of collaboration between technical software engineers and business process stakeholders.
Identify Candidate Formats
Research and identify the popular Big Data file storage formats, such as Parquet, ORC, Avro, JSON, Protobuf, RC file, and others.
Review their features, advantages, and limitations to understand how they align with your requirements.
Performance and Efficiency
Evaluate the file formats’ performance characteristics, such as read and write speeds, compression ratios, and memory usage.
Consider the impact on query performance for different analytical workloads.
Data Schema Evolution
- Assess how well each format supports schema evolution, as Big Data often involves evolving and changing data structures over time.
Data SerDe (Serialization/Deserialization) Support
Evaluate the ease of serialization and deserialization for the file formats in your chosen programming languages.
Consider how easy it is to work with the data format in your data processing pipelines.
Compression and Storage Savings
Compare the storage space savings achieved by each file format.
Analyze how compression affects query performance and overall data processing.
Nothing in world is free, that apply to compression as well. As soon as you need the data decompressed computing cost and other resources needs to be accounted.
Integration with Ecosystem and Tools
Check for support and integration with popular Big Data processing frameworks like Apache Hadoop, Apache Spark, Apache Hive, and others.
Ensure compatibility with your existing data tools and analytics platforms.
Community and Support
Consider the size and activity of the community around each format.
Evaluate the availability of documentation, tutorials, and community support.
Future Proofing
- Analyze the adoption rate and industry trends to ensure that the chosen format is likely to be supported in the long term.
Prototype and Benchmark
Create small prototypes with sample data using different file formats.
Benchmark the performance and query capabilities of each format with your real-world data and analytical workloads.
By following these steps and conducting a thorough evaluation, you can choose the Big Data file storage format that best aligns with your specific needs, performance requirements, and data ecosystem.
Feature Comparisons
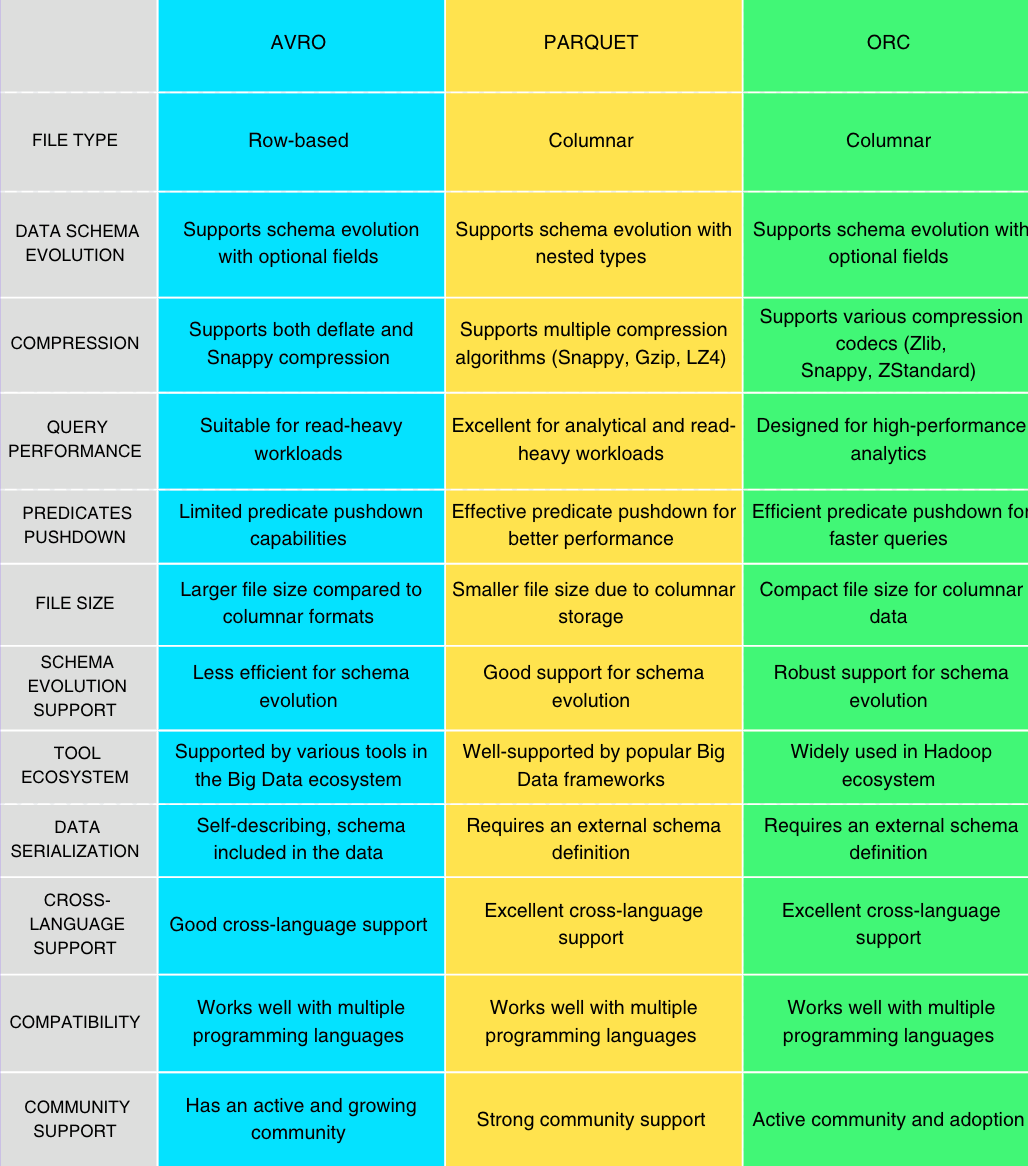
Image Source — By Author
Please note that the choice of file format depends on specific use cases and requirements. While all three formats have their strengths, Parquet and ORC are generally preferred for analytical workloads in Big Data due to their columnar storage and efficient compression, which often result in better query performance and reduced storage costs. However, Avro is still widely used for specific use cases and scenarios where schema evolution or cross-language support is critical.
If establishing a connection interests you, you can find my LinkedIn profile at the following link Aruna Das